
はじめに|AIは「作る」ものになった
ChatGPTが登場してから、生成AIはあっという間に日常に入り込みました。メールの下書き、コードの作成、資料の要約、翻訳——気がつけば「ちょっとAIに聞いてみよう」が当たり前になっています。
でも、こんなふうに感じている人も多いはずです。「AIって便利だけど、結局ブラックボックスだよな」「使うだけで終わるのは、なんか負けた気がする」「自分で作るなんて、専門家じゃないと無理でしょ?」
この記事は、そういう感覚を持っている人に向けて書いています。結論からいうと、生成AIは仕組みを理解すれば「自分で作れる」ものです。大企業や研究者だけのものではありません。部品の組み合わせ方さえわかれば、個人でも、小さなチームでも、業務に特化した自分専用AIを持てます。
そして——「SNSの情報は正しいのか?」という疑問も、実際に手を動かしてみれば自然と答えが出ます。やってみてわかることがある。それがこの記事のもう一つのテーマです。
生成AIとは何か? 一行でいうと
「質問に対して、人間のように答えを作るAI」——これだけです。
「メールを書いて」と言えばメールを書くし、「この文章を短くまとめて」と言えば要約する。「このデータからSQLを作って」と言えばコードを出力する。入力に対して、考えて答えを作る——それが生成AIです。
「AIは一つ」は間違い|部品として考える
多くの人が、AIを「一つの存在」として捉えています。ChatGPTという名前のAIが、クラウドの向こうにいる——そんなイメージです。でも実態は違います。
生成AIは、複数の部品を組み合わせた仕組みです。構造を簡単に表すとこうなります:
入力(あなたの質問)
↓
LLM(考える部分=頭脳)
↓
出力(回答)この「LLM」という部分が、いわばAIの頭脳です。そしてここが重要なのですが、この頭脳は交換可能です。
- OpenAIの「GPT-4」
- Anthropicの「Claude」
- Metaが公開している「Llama 3」
これらは全部、同じ「頭脳」の役割を果たす交換可能な部品です。
つまり生成AIとは「ChatGPT」という固有の存在ではなく、「LLMを中心に組み立てたシステム」のことです。ここを理解するだけで、AIに対する見方がガラッと変わります。
LLMって何?「文章エンジン」と思えばいい
LLMは「Large Language Model(大規模言語モデル)」の略です。本質はシンプルです——「文章を理解して、文章を作るエンジン」。
料理に例えると、LLMは「調理台と火力」です。食材(入力)を受け取って、料理(出力)を作る。何を作るかは、食材と指示次第です。
ただし、ここで重要な現実があります。LLMの種類によって、その「頭の良さ」は全く異なります。 Metaが公開しているLlama 3(7Bクラス)は無料で使えますが、ClaudeやGPT-4のような大規模商用モデルと比べると、推論性能には明確な差があります。これは実際に使ってみると一目瞭然です。
ローカルAIとは?「自分のPCで動くAI」
通常のAI(ChatGPTやClaudeなど)は、インターネット越しにクラウドサーバーで動いています。一方で、ローカルAIとは自分のPCの中でAIを動かすことを指します。外に出ません。完全に手元だけで完結します。
最大の強みは「情報が漏れない」ことです。特に次のような場面で力を発揮します:
- 銀行・医療機関・自治体などセキュリティが厳しい組織
- 顧客情報や機密データを扱う業務
- クラウド利用がポリシー上NGな環境
自治体や公共機関では「個人情報・行政データを外部サーバーに送れない」という制約が厳しく、クラウドAI=NGというケースが多くあります。だからこそ、ローカルAIへの需要は本物であり、単なる趣味の話ではありません。
Ollamaとは?ローカルAIを動かす「土台」
ローカルAIを実現するためのツールとして、現在最もよく使われているのがOllama(オラマ)です。「LLMを自分のPCで動かすための仕組み」と覚えてください。
車に例えると:
- Ollama = 車のフレームとエンジン制御システム
- LLM(Llama 3など) = エンジン本体
実際の手順はシンプルです:
- Ollamaをインストールする(公式サイトからダウンロードするだけ)
ollama run llama3コマンドでLLMをダウンロード- 2回目以降はネット不要——完全オフラインで動作
これだけで「自分のPCで動くAI」が完成します。費用はゼロ。月額も不要。
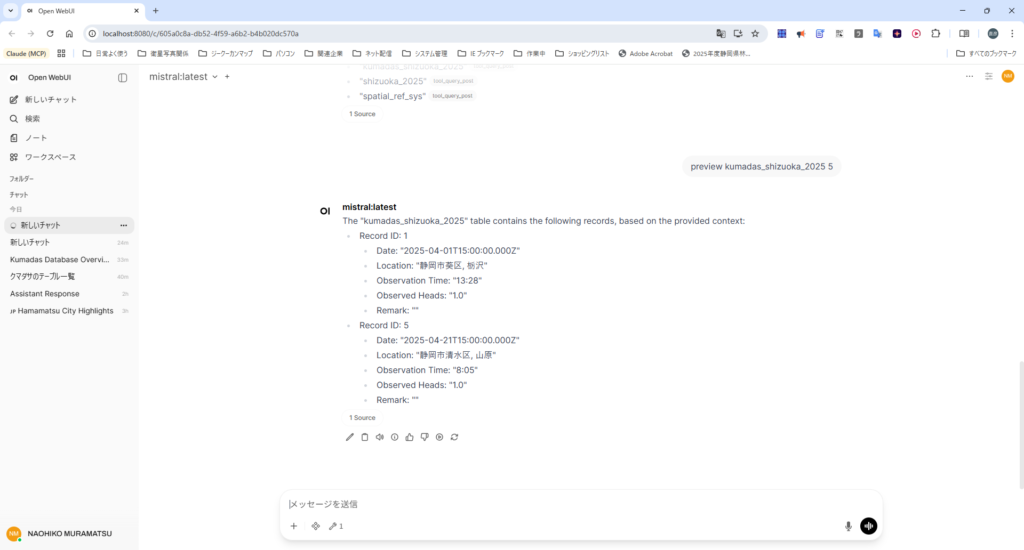
実際にやってみた|ローカルDB連携の構築記録
今回、Ollama + Open WebUI + MCPサーバー + PostgreSQL という構成で、自然文からデータベースへの問い合わせができる環境を実際に構築しました。
構築した内容
- OllamaによるローカルLLM(複数モデル)の導入
- Open WebUIの構築および動作確認
- MCP(Model Context Protocol)サーバーの構築
- PostgreSQL(kumadas)との接続連携
- OpenAPI経由でのSQL実行環境の構築
達成できたこと
「日本語で話しかけるとデータベースを検索してくれる」という一連の流れ(UI → LLM → MCP → DB → 応答)の動作確認に成功しました。テーブル一覧の取得とデータ参照(SELECT)の実行も確認済みです。
たとえば「静岡市葵区のクマダ観測データを見せて」と入力すると、AIがSQLを自動生成し、データベースから結果を返してくれます。これが完全ローカルで動く——それ自体は大きな達成です。
そして直面した現実
ただし、正直に書きます。現時点のローカルLLM(gemma / mistral等の7Bクラス)は、ClaudeやChatGPT-4と比べて推論性能に明確な差があります。
- 応答速度が遅い(GPUなし環境ではCPU推論になるため)
- 複雑なSQL生成の精度が低い
- 日本語の理解・生成が不安定なケースがある
「ハイスペックPCがあれば最強!」とSNSでよく見かけますが、実態は少し違います。GPUがどんなに速くても、モデル自体の知能は変わりません。フェラーリに免許取りたての人を乗せても峠道は攻められない——ハードウェアとモデルは別物です。
これはやってみて初めてわかる感覚です。SNSの情報では伝わらない部分です。
クラウドとローカル|本質的な違いを整理する
実際に両方使ってみると、違いが明確になります:
| ローカルLLM(Ollama) | クラウドAPI(Claude等) | |
|---|---|---|
| データの場所 | 自分のPC内 ✅ | 外部サーバーへ送信 |
| 速度 | 遅い(ハード依存) | 速い |
| 精度 | モデルによる(限界あり) | 高い |
| コスト | 無料 | 従量課金 |
| セキュリティ | 完全ローカル | データが外部へ |
どちらが優れているかではなく、用途と制約によって選ぶものです。機密データを扱う自治体業務ではローカル一択。精度と速度が必要な一般業務ではクラウドが合理的。これが実際に使ってわかる判断軸です。
なお、「ローカルのまま精度を上げる」選択肢として、Qwen2.5:72BやDeepSeek系など大規模モデルがありますが、VRAM 40GB以上が必要で個人・中小規模での導入は現実的ではありません。
今後の対応方針|実用レベルへの道筋
現時点では「ローカルでの一連の仕組みは構築完了」という段階です。今後は以下の方向で実用化を進めます:
- より高性能なローカルLLM(Qwen / DeepSeek系など)の導入検討
- 処理の効率化(定型処理のコマンド化・関数化)
- LLM依存部分の削減による高速化
- 機密性の低いデータ処理へのクラウドAPIの部分活用
注意点|夢を見すぎないための現実認識
正直に書きます。
- 誤答は必ずある(ハルシネーション):重要な判断には人間の確認フローを
- PC性能は必要:GPU(VRAM 8GB以上)があると快適。なくても動くが遅い
- 運用設計が重要:モデル選定、プロンプト設計、精度担保——ここに一番時間がかかる
- SNSの情報は盛られている:デモ動画は都合のいい例だけ、ハイスペック環境で撮影されたもの
まとめ|AIを使う側から、作る側へ
この記事で伝えたかったことを整理します:
- 生成AIは部品の組み合わせ——LLMは交換可能な頭脳
- Ollamaで自分のPCでAIが動く——ネット不要、費用不要
- ローカルAIの最大の価値は「情報が外に出ない」こと
- ただし、LLMの品質差は歴然——実際に使ってみないとわからない
- SNSの情報は参考程度に——手を動かして体感することが一番の学び
一度仕組みを理解すると、世の中のAIサービスがどう作られているか見えてくるようになります。AIを使う側から、AIを作る側へ。そこには大きな景色の違いがあります。
最初の一歩は、Ollamaをインストールしてみることです。難しくありません。そして「SNSで言われていることは本当か?」を自分の手で確かめてみてください。やってみてわかることが、必ずあります。
#ローカルAI #OpenWebUI #Ollama #MCP #PostgreSQL #LLM #AIエージェント #DX #データ活用 #GIS


コメント